
WordNet is a large lexical database of English. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations. The resulting network of meaningfully related words and concepts can be navigated with the browser. WordNet's structure makes it a useful tool for computational linguistics and natural language processing.
Version: 3.1.0

WordNet is a large lexical database of English. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations. The resulting network of meaningfully related words and concepts can be navigated with the browser. WordNet's structure makes it a useful tool for computational linguistics and natural language processing.
Version: 3.0.0
This is the Variation and Translation module of the Lemon collection of lexicographic vocabularies. It can be used to represent relations between lexical entries and lexical senses that are variants of each other.
Version: 1.0.0
This is the Syntactic Frames module of the Lemon collection of lexicographic vocabularies.
Use this vocabulary to describe syntactic frames for categories of words.
For example, transitive verbs (“to own”) require a syntactic subject and a syntactic object, relational nouns (“mother of”) require a prepositional object, adjectives require a noun to modify.
Version: 1.0.0
This is the Ontology Lexicon vocabulary of the Lemon collection of lexicographic vocabularies.
Version: 1.0.0

Languages are an endangered heritage
According to Ethnologue, the number of human languages currently used in the world amounts to almost 7,000. About half of them could be extinct before the end of this century. Only a small fraction of them is supported by some writing system and have written heritage, and among those, still less are used in modern information systems and on the Web. A good indication of the number of languages used on the Web is provided by the multilingual editions of Wikipedia, to-date 285 different languages, that is less than 5% of all known languages. Ranking of languages by importance of their respective Wikipedia is a fairly good indicator for the Web influence of their communities of speakers, but very different from the ranking based on the number of speakers.
We need languages as Linked Data
In current XML and RDF practice, languages are identified by tags, typically used in the xml:lang attribute. The allowed values of tags are defined by BCP 47. Those language tags are typically used for rdfs:label or rdfs:comment, and allow the filtering of such elements of description by language, for example in SPARQL queries. But they do not provide support for queries such as:
- “Can I find native speakers of Bengali in Berlin?”
- “Which books by Victor Hugo are translated in Arabic?”
- “Is this software documented in Chinese?”
To answer such queries, languages need to be represented as resources, likely to be linked to other resources representing books, people, organizations, places, events, products … through dedicated properties. Such properties can be found in the Lingvoj Ontology. URIs for languages have been defined in lingvoj.org namespace since 2007, and many other URIs have been defined afterwards in the linked data cloud. Since 2010 lingvoj.org URIs mainly redirect to those of lexvo.org.
Version: 2.33.0
This is the Linguistic Metadata vocabulary of the Lemon collection of lexicographic vocabularies. It can be used to describe metadata for lexicographic datasets. This vocabulary should be used in combination with generic metadata vocabularies such as Dublin Core, PROV, DCAT, and VoID.
Lime distinguishes three main metadata entities:
- the reference dataset (describing the semantics of the domain, e.g., the ontology), 2.the lexicon (being a collection of lexical entries),
- the concept set (an optional set of lexical concepts, bearing a conceptual backbone to a lexicon).
Version: 1.0.0

Lexvo.org brings information about languages, words, characters, and other human language-related entities to the Linked Data Web and Semantic Web. The Linked Data Web is a worldwide initiative to create a Web of Data that exposes the relationships between entities in our world. Lexvo.org adds a new perspective to this Web by exposing how everything in our world is connected in terms of language, e.g. by considering semantic relationships between multilingual labels (like book or New York). Lexvo not only defines global IDs (URIs) for language-related objects, but also ensures that these identifiers are dereferenceable and highly interconnected as well as externally linked to a variety of resources on the Web. Some of the main features up to date.
Version: 2013-02-09

LexInfo is an ontology that was defined during the Monnet Project to provide data categories for the Lemon model. It has since since been updated with the new OntoLex-Lemon model of the OntoLex community group. LexInfo is now developed on GitHub.
Version: 1.0.0
This is the lexicography module of the Lexicon Model for Ontologies (lemon). It is a result of the work of the Ontology Lexicon community group (OntoLex). The module is targeted at the representation of dictionaries and any other linguistic resource containing lexicographic data, and addresses structures and annotations commonly found in lexicography. This module operates in combination with the lemon core module, referred to as OntoLex.
Version: 1.0.0
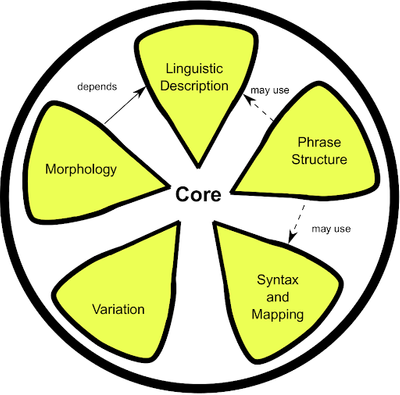
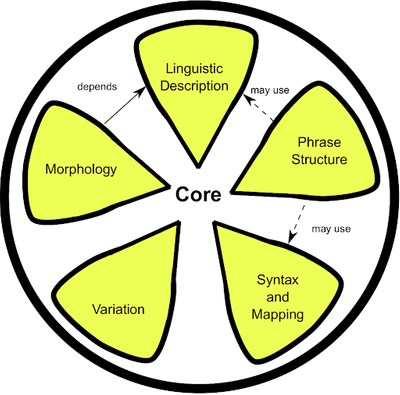
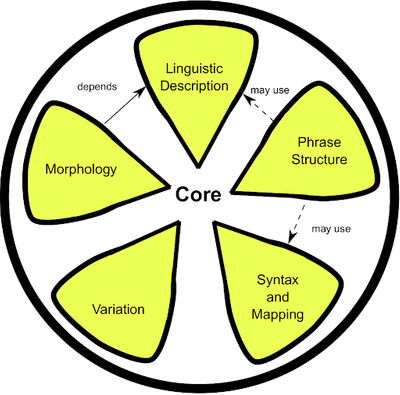
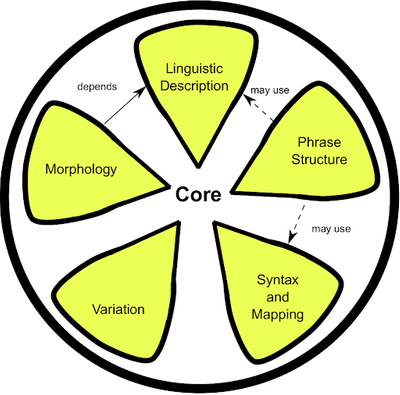
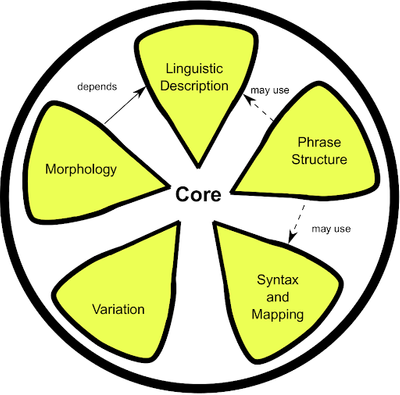
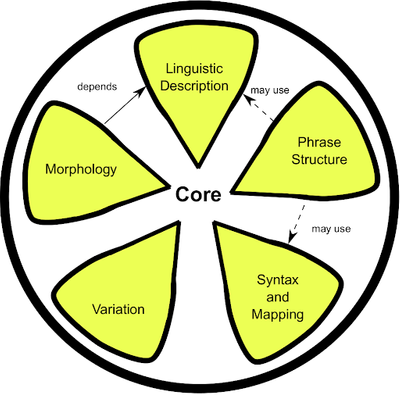
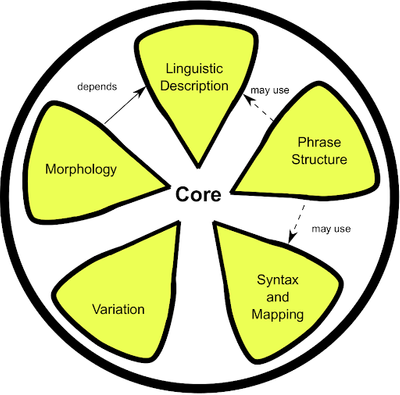
Lemon: The lexicon model for ontologies is designed to allow for descriptions of lexical information regarding ontological elements and other RDF resources. Lemon covers mapping of lexical decomposition, phrase structure, syntax, variation, morphology, and lexicon-ontology mapping.
Version: 1.0.0

ISO 639 is a set of standards by the International Organization for Standardization that is concerned with representation of names for languages and language groups.
It was also the name of the original standard, approved in 1967 (as ISO 639/R) and withdrawn in 2002. The ISO 639 set consists of five parts.
Version: 1.0.0

The i18n namespace is used for describing combinations of language tag and base direction in RDF literals.
It is used as an alternative mechanism for describing the BCP47 language tag and base direction of RDF literals that would otherwise use the xsd:string or rdf:langString datatypes.
Version: 1.0.0

GOLD is an ontology for descriptive linguistics. It gives a formalized account of the most basic categories and relations (the ‘atoms’) used in the scientific description of human language. GOLD is intended to capture the knowledge of a well-trained linguist, and can thus be viewed as an attempt to codify the general knowledge of the field. It will facilite automated reasoning over linguistic data and help establish the basic concepts through which intelligent search can be carried out. Furthermore, GOLD is meant to be compatible with the general goals of the Semantic Web.
Version: 2010

GOLD is an ontology for descriptive linguistics. It gives a formalized account of the most basic categories and relations (the ‘atoms’) used in the scientific description of human language. GOLD is intended to capture the knowledge of a well-trained linguist, and can thus be viewed as an attempt to codify the general knowledge of the field. It will facilite automated reasoning over linguistic data and help establish the basic concepts through which intelligent search can be carried out. Furthermore, GOLD is meant to be compatible with the general goals of the Semantic Web.
Version: 2009

GOLD is an ontology for descriptive linguistics. It gives a formalized account of the most basic categories and relations (the ‘atoms’) used in the scientific description of human language. GOLD is intended to capture the knowledge of a well-trained linguist, and can thus be viewed as an attempt to codify the general knowledge of the field. It will facilite automated reasoning over linguistic data and help establish the basic concepts through which intelligent search can be carried out. Furthermore, GOLD is meant to be compatible with the general goals of the Semantic Web.
Version: 2008
This is the Decomposition module of the Lemon collection of lexicographic vocabularies.
Decomposition is the process of indicating which elements constitute a multi-word or compound lexical entry.
Version: 1.0.0

The Argument Model Ontology (AMO) is an ontology that allows to describe argumentation according to the 'Toulmin Model of Argument'.
Version: 1.0.0