
The purpose of VAEM is to provide, by import, a foundation for commonly needed resources for metadata on an ontology.
VAEM stands for “Vocabulary for Attaching Essential Metadata”. What VAEM regards as essential metadata is data about dates and times, confidentiality, and other characterisitic qualifiers of the ontology, but also references to where a ontology is documented and where to find ontology registration for governance, attribution and provenance. VAEM makes use of some properties from the Dublin Core Terms vocabulary.
Version: 2.0.0
Ontology for PREMIS 3, the international standard for metadata to support the preservation of digital objects and ensure their long-term usability.

An RDF vocabulary for relating SW vocabulary terms to their status.
Version: 2.0.0

VoID is an RDF Schema vocabulary for expressing metadata about RDF datasets. It is intended as a bridge between the publishers and users of RDF data, with applications ranging from data discovery to cataloging and archiving of datasets. This document is a detailed guide to the VoID vocabulary. It describes how VoID can be used to express general metadata based on Dublin Core, access metadata, structural metadata, and links between datasets. It also provides deployment advice and discusses the discovery of VoID descriptions.
Version: 1.0.0

VOAF is a vocabulary specification providing elements allowing the description of vocabularies (RDFS vocabularies or OWL ontologies) used in the Linked Data Cloud. In particular it provides properties expressing the different ways such vocabularies can rely on, extend, specify, annotate or otherwise link to each other. It relies itself on Dublin Core and VoID. The name of the vocabulary makes an explicit reference to FOAF because VOAF can be used to define networks of vocabularies in a way similar to the one FOAF is used to define networks of people.
Version: 2.3.0

A vocabulary for annotating descriptions of vocabularies with examples and usage notes.
Version: 1.0.0

The purpose of VAEM is to provide, by import, a foundation for commonly needed resources for metadata on an ontology.
VAEM stands for “Vocabulary for Attaching Essential Metadata”. What VAEM regards as essential metadata is data about dates and times, confidentiality, and other characterisitic qualifiers of the ontology, but also references to where a ontology is documented and where to find ontology registration for governance, attribution and provenance. VAEM makes use of some properties from the Dublin Core Terms vocabulary.
Version: 2.0.0

This ontology provides a set of basic metadata annotations for use in describing Object Management Group (OMG) specifications, standards, and documents. It was recommended for use by the OMG Architecture Board (AB) in OMG standard ontologies, vocabularies and other models at the March 2013 Reston meeting.
The annotations defined herein extend properties defined in the Dublin Core Metadata Terms Vocabulary and in the W3C Simple Knowledge Organization System (SKOS) Vocabulary, and have been customized to support the OMG specification development process. Note that any of the original properties provided in Dublin Core and SKOS can be used in addition to the terms provided herein. However, any Dublin Core terms that are not explicitly defined as OWL annotation properties below must be so declared in the ontologies that use them.
Version: 2013-03-01

The Creative Commons Rights Expression Language (CC REL) lets you describe copyright licenses in RDF. For more information on describing licenses in RDF and attaching those descriptions to digital works, see CC REL in the Creative Commons wiki.
Version: 1.0.0

Open Metadata Registry Status Vocabulary
Version: 1.0.0

The MetaVocab vocabulary (for lack of a better name) includes the terms necessary for describing vocabularies.
We should also take a look at the RDDL work to see how we can include those definitions in this vocabulary.
Version: 1.0.0
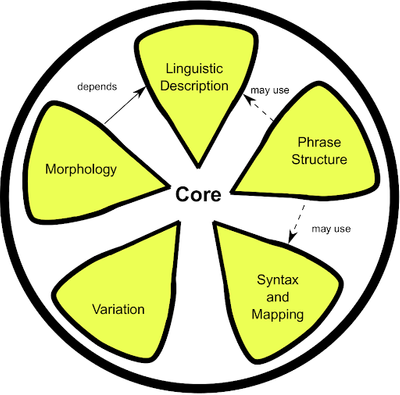
This is the Linguistic Metadata vocabulary of the Lemon collection of lexicographic vocabularies. It can be used to describe metadata for lexicographic datasets. This vocabulary should be used in combination with generic metadata vocabularies such as Dublin Core, PROV, DCAT, and VoID.
Lime distinguishes three main metadata entities:
- the reference dataset (describing the semantics of the domain, e.g., the ontology), 2.the lexicon (being a collection of lexical entries),
- the concept set (an optional set of lexical concepts, bearing a conceptual backbone to a lexicon).
Version: 1.0.0

Representation of quality categories and dimensions from Amrapali Zaveri, Anisa Rula, Andrea Maurino, Ricardo Pietrobon, Jens Lehmann, Sören Auer. 2016. “Quality Assessment for Linked Data: A Survey” in Semantic Web, Vol. 7, No. 1, pp. 63-93 (https://dx.doi.org/10.3233/SW-150175).
Version: 1.0.0

The Dataset Usage Vocabulary (DUV) is used to describe consumer experiences, citations, and feedback about datasets from the human perspective.
Datasets published on the Web are accessed and experienced by consumers in a variety of ways, but little information about these experiences is typically conveyed. Dataset publishers many times lack feedback from consumers about how datasets are used. Consumers lack an effective way to discuss experiences with fellow collaborators and explore referencing material citing the dataset. Datasets as defined by DCAT are a collection of data, published or curated by a single agent, and available for access or download in one or more formats. The Dataset Usage Vocabulary (DUV) is used to describe consumer experiences, citations, and feedback about the dataset from the human perspective.
By specifying a number of foundational concepts used to collect dataset consumer feedback, experiences, and cite references associated with a dataset, APIs can be written to support collaboration across the Web by structurally publishing consumer opinions and experiences, and provide a means for dataset consumers and producers advertise and search for published open dataset usage.
Version: 1.0.0

The Data Quality Vocabulary (DQV) provides a framework in which the quality of a dataset can be described, whether by the dataset publisher or by a broader community of users. It does not provide a formal, complete definition of quality, rather, it sets out a consistent means by which information can be provided such that a potential user of a dataset can make his/her own judgment about its fitness for purpose.
Version: 1.0.0

This document is an up-to-date specification of all metadata terms maintained by the Dublin Core Metadata Initiative, including properties, vocabulary encoding schemes, syntax encoding schemes, and classes.
This document is an up-to-date, authoritative specification of all metadata terms maintained by the Dublin Core Metadata Initiative. Included are the fifteen terms of the Dublin Core Metadata Element Set, which have also been published as IETF RFC 5013, ANSI/NISO Standard Z39.85-2007, and ISO Standard 15836:2009.
Version: 1.1.0

The DCMI Type Vocabulary was created in 2001. It defines classes for basic types of thing that can be described using DCMI metadata terms.
Version: 2012-06-14

DCAT is an RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web. This document defines the schema and provides examples for its use.
DCAT enables a publisher to describe datasets and data services in a catalog using a standard model and vocabulary that facilitates the consumption and aggregation of metadata from multiple catalogs. This can increase the discoverability of datasets and data services. It also makes it possible to have a decentralized approach to publishing data catalogs and makes federated search for datasets across catalogs in multiple sites possible using the same query mechanism and structure. Aggregated DCAT metadata can serve as a manifest file as part of the digital preservation process.
Version: 2.0.0

This dataset provides possible statuses for datasets. It has been developed specifically for the EU Open Data Portal.
Version: 2016-09-21

This vocabulary defines a set of terms for describing changes to resource descriptions.
It introduces the notion of a ChangeSet which encapsulates the delta between two versions of a resource description. In this context a resource description is the set of triples that in some way comprise a description of a resource. The delta is represented by two sets of triples: additions and removals. A ChangeSet can be used to modify a resource description by first removing all triples from the description that are in the removals set and adding the triples in the additions set.
Version: 2009-05-18

Vocabulary for representing content in RDF. This vocabulary is intended to provide a flexible framework within different usage scenarios to semantically represent any type of content, be it on the Web or in local storage media. For example, it can be used by web quality assurance tools such as web accessibility evaluation tools to record a representation of the assessed web content, including text, images, or other types of formats. In many cases, it can be used together with HTTP Vocabulary in RDF, which allows quality assurance tools to record the HTTP headers that have been exchanged between a client and a server. This is particularly useful for quality assurance testing, conformance claims, and reporting languages like the W3C Evaluation And Report Language (EARL).
Version: 1.0.0

This is a capability meta-model that is presented as an RDF schema for describing capabilities as an action category and a set of properties. Additionally, this schema defines the possible property value types that can be considered when modelling capabilities: ConditionalValue, ConstrainedValue, EnumerationValue, DynamicValue and RangeValue.
Version: 2015-05-20

This is the RDF encoding of the Asset Description Metadata Schema, originally developed under the European Union's ISA Programme and further developed by the W3C Government Linked Data Working Group. It re-uses terms from several other vocabularies, notably Dublin Core, with elements of SKOS, FOAF and more.
Version: 1.0.0

This data set is the result of a research project done by students from the VU and UvA in the course Knowledge Representation on the Web.
Metadata for YALC (Yet Another LOD Cloud), a registry of Linked Open Datasets.